Lemon is a proposed model for modeling lexicon and machine-readable dictionaries and linked to the Semantic Web and the Linked Data cloud. It was designed to meet the following challenges
Lemon was developed by the Monnet project as a collaboration between:
CITEC at Bielefeld University, DERI at the National University of Ireland, Galway, Universidad Politécnica de Madrid and the Deutsche Forschungszentrum für Künstliche Intelligenz
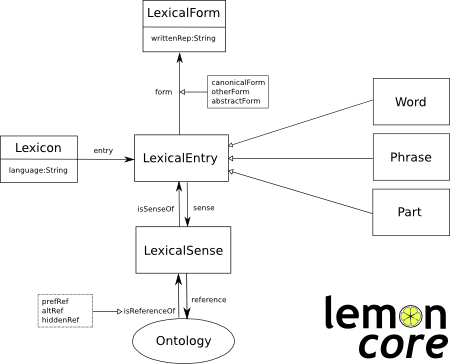
To see how to get started with the model see our guide
For full documentation you may consult the Lemon Cookbook
Lemon API is a Java-based interface for using lemon that is compatible with all major platforms. In addition, there is a Wiki-like site for manipulating and publishing lemon data, called Lemon Source. This includes a service for generating lexica from ontologies.
Lemon is still under development and we welcome contributions. If you wish to get involved please join the W3C OntoLex Community Group